Bifrost: End-to-End Evaluation and Optimization of Reconfigurable DNN Accelerators
This post gives a brief overview of the paper *“Bifrost: End-to-End Evaluation and Optimization of Reconfigurable DNN Accelerators”**, which I was 2nd author to Axel Stjerngren. The paper was published at ISPASS 2022, and you can view the paper on IEEE Xplore if you’ve got access, or on arXiv for free. I presented a 15 minute presentation on the paper at the conference.
To accelerate DNN inference, researchers are developing a wide range of hardware accelerators (e.g., NPUs, TPUs, or micro-architecture extensions to GPUs). An emerging topic in this domain is reconfigurable DNN hardware accelerators. These are systems where the Network-on-Chip circuits can be configured to alter the dataflow within the accelerator, which can improve inference in terms of time and energy for a given layer of a DNN.
However, since these architectures are an emerging area, there are still many questions to be answered around both the design of the hardware, and the approach taken for its configuration (also known as mapping).
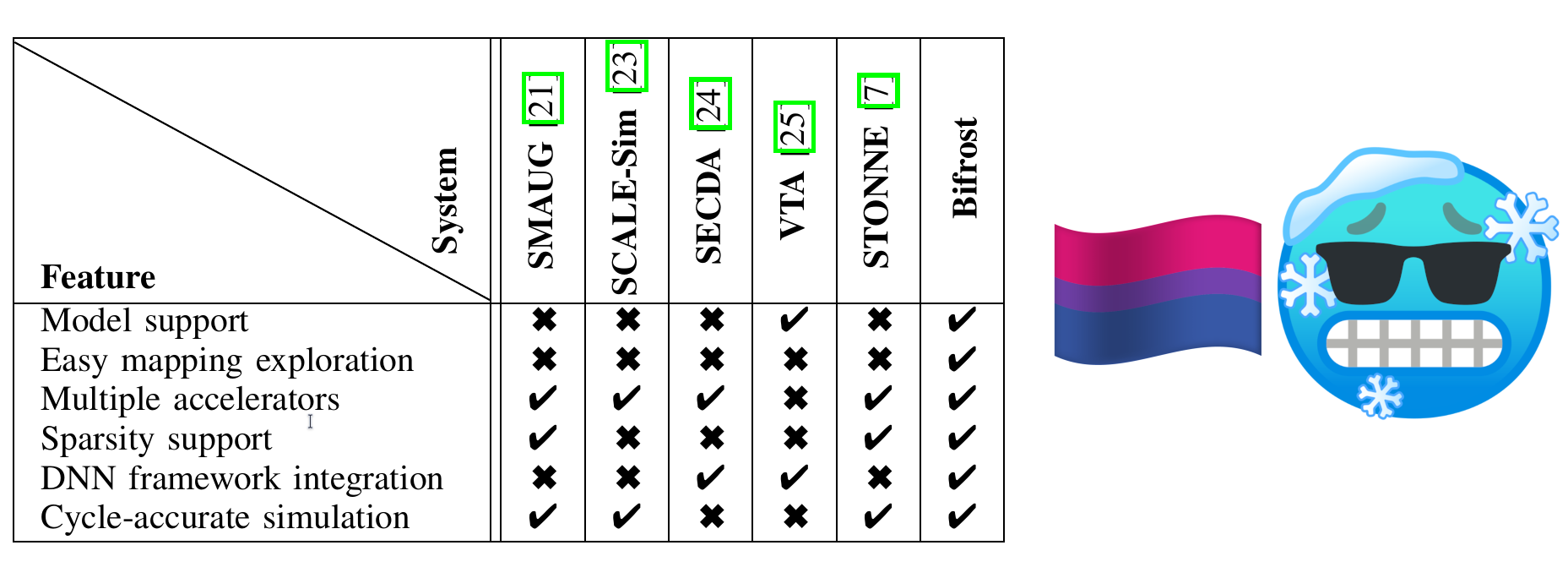
To help answer these questions, a simulator for reconfigurable DNN hardware accelerators was developed, known as STONNE. However, STONNE has a number of drawbacks when it comes to usability, such as requiring manual steps to evaluate models, only supporting models from PyTorch, and not cleanly integrating mapping tools.
Thus, to address these issues, we proposed Bifrost, an open source tool which combines the power of STONNE with the advantages of the TVM deep learning compiler framework to make it easier to explore the trade-offs in reconfigurable DNN hardware accelerators.
The paper discusses the design of Bifrost, and our novel auto-tuning module which can provide optimized mappings even when no specialised mapping tool is available. We compare against other simulation tools, and provide an evaluation to demonstrate the functionality of Bifrost using 2 different accelertator architectures.
You can read the paper it on arXiv and IEEE Xplore, or check out the code on GitHub.