Cheesing the Railcard System for Fun and Discounts

I recently applied for a Railcard for my partner who was visiting the UK. They were eligible for a 25-30 Railcard, which offers a discount on train journeys. However, they are from Belgium, which I found represented an edge case in the sign-up form, making it appear impossible to apply for the Railcard.
This is the story of how I cheesed the system, and was able to get the discount for them despite this.
For those unfamiliar, a Railcard is a discount card for the UK rail network. It’s especially beneficial for students, senior citizens, and frequent travellers looking to save on train fares. It has an annual fee, but if you’re going to be making a few journeys, it’s worth it, since it gives you a third off the price of your ticket. The discount on this journey alone covered the cost of the Railcard, making it a worthwhile investment for future trips.
The Problem
One of the requirements was a form of ID, such as a UK driver’s license or a passport from almost any country. The passport was the obvious choice, and thus I was presented with the following prompt:
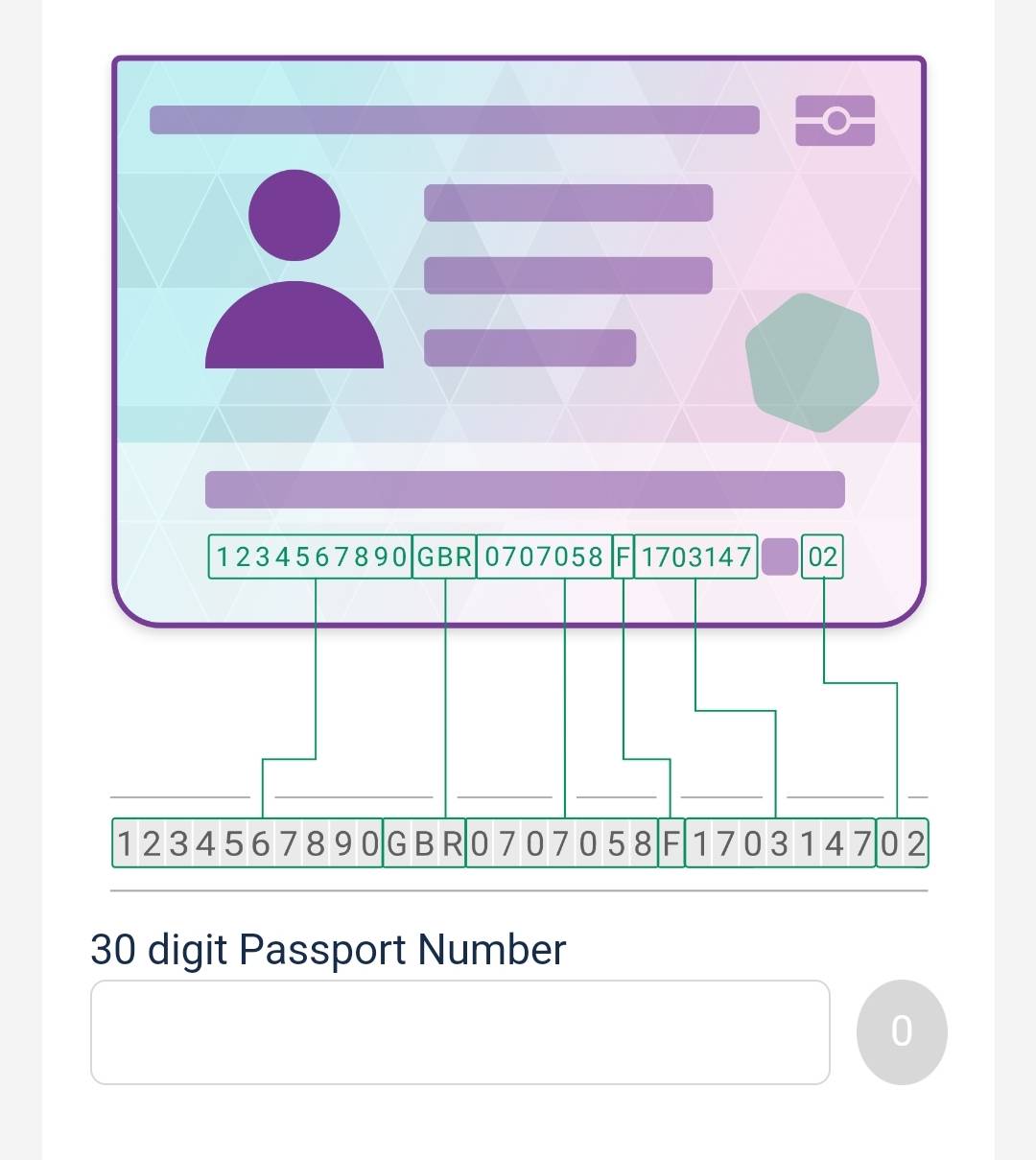
Having to type out 30 characters is a little much (I’m a busy man 😎), but a discount is a discount. You might recognise the “machine readable” part of the passport, which is the two lines of text at the bottom of the passport.
An example from wikimedia is below:
{kind=link}

I used OCR software to extract the text from my partner’s passport and pasted in the relevant characters. However, the form refused to validate, because I had only entered 29 characters rather than 30. I double checked what I’d entered, and the passport, and it was definitely 29 characters long. What’s going on?
The Hunt
I inspected the relevant components which made up the number, and noticed that on my partner’s passport, the first section before the country code was only 9 characters, whereas in the example given it was 10.

As a test, I tried adding a 0 in there to pad it, but it didn’t work. I realised that the first 9 characters is the passport number and the final character is a validity checksum. Therefore, I couldn’t just add zeros without making the checksum fail.
With further inspection, I realised that the Belgian passport number is only 8 characters long. This is unusual — a random sample of some of my other pals confirmed that pretty much every one has 9 characters.
I guess the Belgian government thought there wasn’t enough Belgians to warrant the extra digit?
Later, when doing this writeup, I checked how the checksum is implemented, and it is the Luhn algorithm (aka “mod 10”). It’s widely used in credit cards and other ID systems. It helps ensure that the number is entered correctly.
Now I understood the issue, but I was still left with the problem of the Railcard registration form, which did not account for this edge case.
One approach could be to see if the validity check was client side. In that way I could simply edit the code running on my browser. However, before I went that far, I recalled a niche piece of knowledge I picked up a few years ago.
The Cheese
Anecdote time! In 2018, when the Dutch added a third sex indicator to their passports (beyond just M or F, namely X), they implemented in a particular way.
I remember reading about this at the time, and thought it was interesting for a few technical reasons. Included in some of the articles I read was some info about how they handled the machine readable part of the passport.
You can imagine that over the decades a lot of code has been written to handle passport data, before this X marker was added. It’s possible (and likely) that “X” was not considered in the data schema of the software, and thus a lot of software might break, since they assumed it could only be M or F.
This sounds similar to how lazy programmers of the 20th century encoded the year as a 2 digit number (e.g., 98, 64), exposing us to the Y2K problem.
Similarly, it’s safe to assume that all sorts of systems across the world that handle passport data assumed that sex was binary (rather than bimodal). Robust schema design is an art!
Therefore, to try and reduce these problems, although “X” is what is written on the main part of the Dutch passport that people see, the machine readable part is handled a bit differently. Instead of adding X explicitly as a third choice, if you read where the marker would be in a Dutch passport (for someone with an X) you’ll see… nothing.
Well, not quite nothing.
Instead, you’ll see just another <, which serves as a filler (or empty) character in the machine readable passport format.
So “X” sex actually represents “undefined” sex, which is probably more accurate anyway.
Most systems that read the machine readable part of the passport would just skip over this character, and continue as normal.
And existing databases should be able to handle missing data gracefully, since it’s a common enough occurrence.
For our purposes, perhaps you can see how we can use this.
< is essentially a skip character — could we use this to pad our short Belgian passport number without failing the checksum?
Will the Railcard website validation handle this okay?
It doesn’t document this as an option, but it’s worth a try.
And… it worked, and all it took was some knowledge of the machine readable passport number format. Something that I’m sure everyone is expected to know /s.
Conclusion
As you can imagine, I’ve contacted the UK Railcard operator about this issue. Belgians are edge cases, but that doesn’t mean they don’t deserve the same things as the rest of us, with the same level of convenience.
Overall, this was a fun little “exploit”, as it gave me the satisfaction of using somewhat obscure trivia I’d picked up.
Crucial to this was that the underlying validation system was able to handle the < workaround, but really it should have been documented, or ideally the form should have been more flexible.
For example, it could have asked for the different parts separately.
I’m glad I was able to help my lovely partner get a discount on their train journey.
2025 Update: A Czech colleague informed me that they have a similar issue with their passport number, and were able to use the same < trick to get a Railcard for their children.