DNN64: An ML Compiler Toolchain for the Nintendo 64 (Part 2) --- Weighty Matters

This post is the second in my DNN64 series, where I discuss my project of compiling and accelerating deep neural networks (DNNs) on the Nintendo 64 system. My first post is available here. This post will talk about some of the challenges we face regarding the limited memory of the console compared to the high memory requirements of DNNs, and changes we need to make to our code generator to increase our efficiency and thus increase the size of the models we can run. In particular, we’ll look at this from the perspective of the DNN weights (also known as parameters).
Weight loading
As discussed in the first post, we’re using MicroTVM to generate C definitions for our DNN.
Let’s take a look at some of the C code generated by an unmodified version of TVM for a simple three layer network.
I’m going to focus on two C files in particular, which should be generated under codegen/host/src, with names like default_lib0.c and default_lib1.c.
The first file contains the main invocation of our DNN:
TVM_DLL int32_t tvmgen_default___tvm_main__(
float *dense_4_input_buffer_var, float *Identity_buffer_var,
uint8_t *global_const_workspace_0_var, uint8_t *global_workspace_1_var) {
// constant_X_let are our weight matrices, which we access from the
// global_const_workspace_0_var, a contiguous memory region with all our
// weights in it
void *constant_0_let = (&(global_const_workspace_0_var[1216]));
void *constant_1_let = (&(global_const_workspace_0_var[1152]));
void *constant_5_let = (&(global_const_workspace_0_var[1280]));
void *constant_2_let = (&(global_const_workspace_0_var[0]));
void *constant_3_let = (&(global_const_workspace_0_var[1088]));
void *constant_4_let = (&(global_const_workspace_0_var[1024]));
// sid_X_let are our intermediate results, which we store in a workspace
// buffer
void *sid_1_let = (&(global_workspace_1_var[96]));
void *sid_4_let = (&(global_workspace_1_var[0]));
void *sid_7_let = (&(global_workspace_1_var[64]));
// We then execute every layer of our model one after another, returning 0 if
// the execution was successful. Our output should be stored in
// Identity_buffer_var
if (tvmgen_default_fused_reshape(dense_4_input_buffer_var, sid_1_let,
global_const_workspace_0_var,
global_workspace_1_var) != 0)
return -1;
if (tvmgen_default_fused_nn_contrib_dense_pack_add_nn_relu(
sid_1_let, constant_0_let, constant_1_let, sid_4_let,
global_const_workspace_0_var, global_workspace_1_var) != 0)
return -1;
if (tvmgen_default_fused_nn_contrib_dense_pack_add_nn_relu_1(
sid_4_let, constant_2_let, constant_3_let, sid_7_let,
global_const_workspace_0_var, global_workspace_1_var) != 0)
return -1;
if (tvmgen_default_fused_nn_contrib_dense_pack_add(
sid_7_let, constant_4_let, constant_5_let, Identity_buffer_var,
global_const_workspace_0_var, global_workspace_1_var) != 0)
return -1;
return 0;
}
As you can see, we prepare pointers to our weight and activation arrays first (e.g., *constant_0_let and *sid_1_let respectively), then run each layer of our DNN.
These buffers are prepared in the other C file:
// Our workspace, comprised of 160 bytes
__attribute__((section(".bss.noinit.tvm"),
aligned(8))) static uint8_t global_workspace[160];
// Our weight arrays, in hex format
__attribute__((section(".rodata.tvm"), )) static struct global_const_workspace {
float constant_2_let[256]
__attribute__((aligned(16))); // 1024 bytes, aligned offset: 0
float constant_4_let[16]
__attribute__((packed, aligned(16))); // 64 bytes, aligned offset: 1024
float constant_3_let[16]
__attribute__((packed, aligned(16))); // 64 bytes, aligned offset: 1088
float constant_1_let[16]
__attribute__((packed, aligned(16))); // 64 bytes, aligned offset: 1152
float constant_0_let[16]
__attribute__((packed, aligned(16))); // 64 bytes, aligned offset: 1216
float constant_5_let[1]
__attribute__((packed, aligned(16))); // 4 bytes, aligned offset: 1280
} global_const_workspace = {
.constant_2_let =
{-0x1.4a62b2p-2, -0x1.8c75ap-3, -0x1.4457fp-5, 0x1.ee096ap-3,
-0x1.aa9a3ep-3, 0x1.4e7fd4p-2, 0x1.22d84ep-2, -0x1.fcbcep-5,
// and so on
},
.constant_4_let = {-0x1.34a976p-1, -0x1.f681e2p-1, 0x1.0a4db6p-1,
0x1.315aeep-1, 0x1.bb42f6p-1, 0x1.874a72p+0,
// and so on
},
// our other weight arrays get assigned their values
.constant_5_let = {-0x1.928ffp-2},
}; // of total size 1284 bytes
As you can see, we are hard coding the weights in this C file, meaning they will be compiled into our executable. We can then access them via the pointers we initialised in our main function. All very well and good, but we have a problem. If we try and compile a larger model, our individual object files are generated correctly, but we get a linker error, for example:
/opt/libdragon/bin/../lib/gcc/mips64-elf/13.2.0/..////mips64-elf/bin/ld:
region men' overflowed by 132146288 bytes
collect2: error: Id returned 1 exit status
make: (Makefile:46: build/dnn64.elf] Error 1
What’s happening here? Clearly we are running out of memory — the N64 only has 4MB afterall — but why is this happening, shouldn’t MicroTVM be optimised for microcontrollers? To answer this question we need to talk briefly about ELF files and linker configuration.
ELF 🧝 and (lib)dragon 🐉
You might have noticed this snippet in our weight definition code section(".rodata.tvm").
This is to indicate to the compiler that this is “read-only data”, and should be placed in the appropriate part of the ELF file.
But what is an ELF file?
Standing for Executable and Linkable Format, ELF files are a standard format for executable programs, especially in UNIX-like environments. It defines where and how our executable code is stored, along with any data it requires, and metadata that can be used to help interpret it correctly. It’s the format used by the N64, all of the Sony PlayStations, Linux, FreeBSD, Fuchsia, and more.
Below is a diagram showing the main components and structure of an ELF file, to give you an idea of what that looks like:
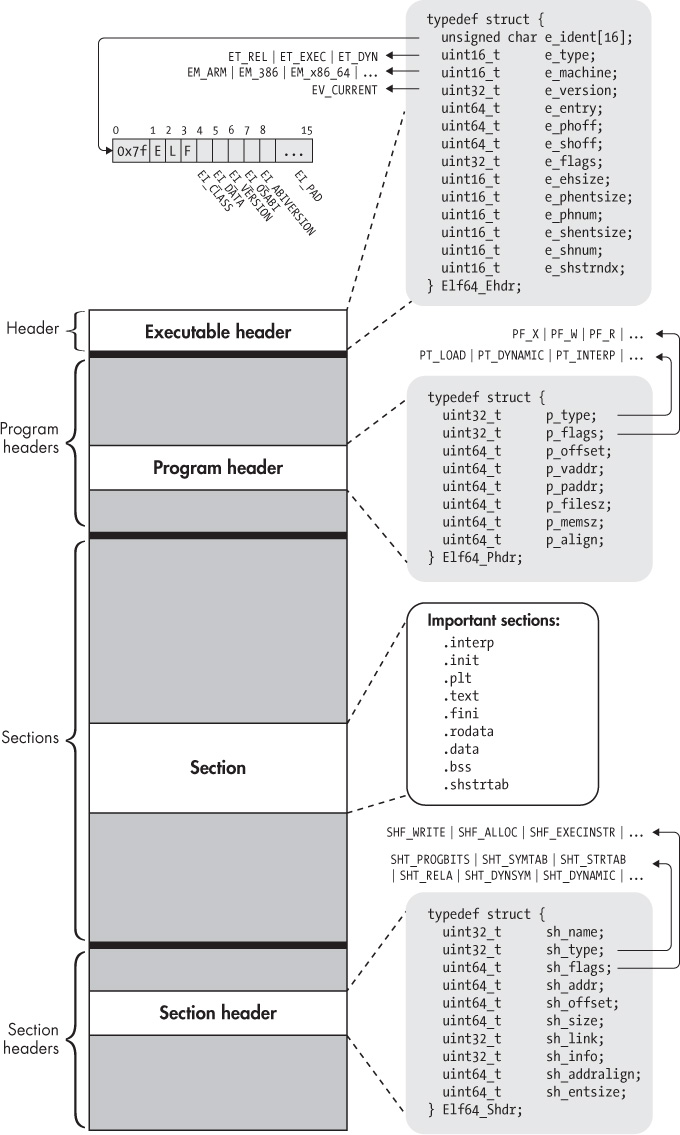
.init, .text, .rodata, .bss.And here’s a more detailed diagram of how it’s structured, from Ange Albertini. If you’re interested in learning more, the ELF Format Cheatsheet gives some great information.
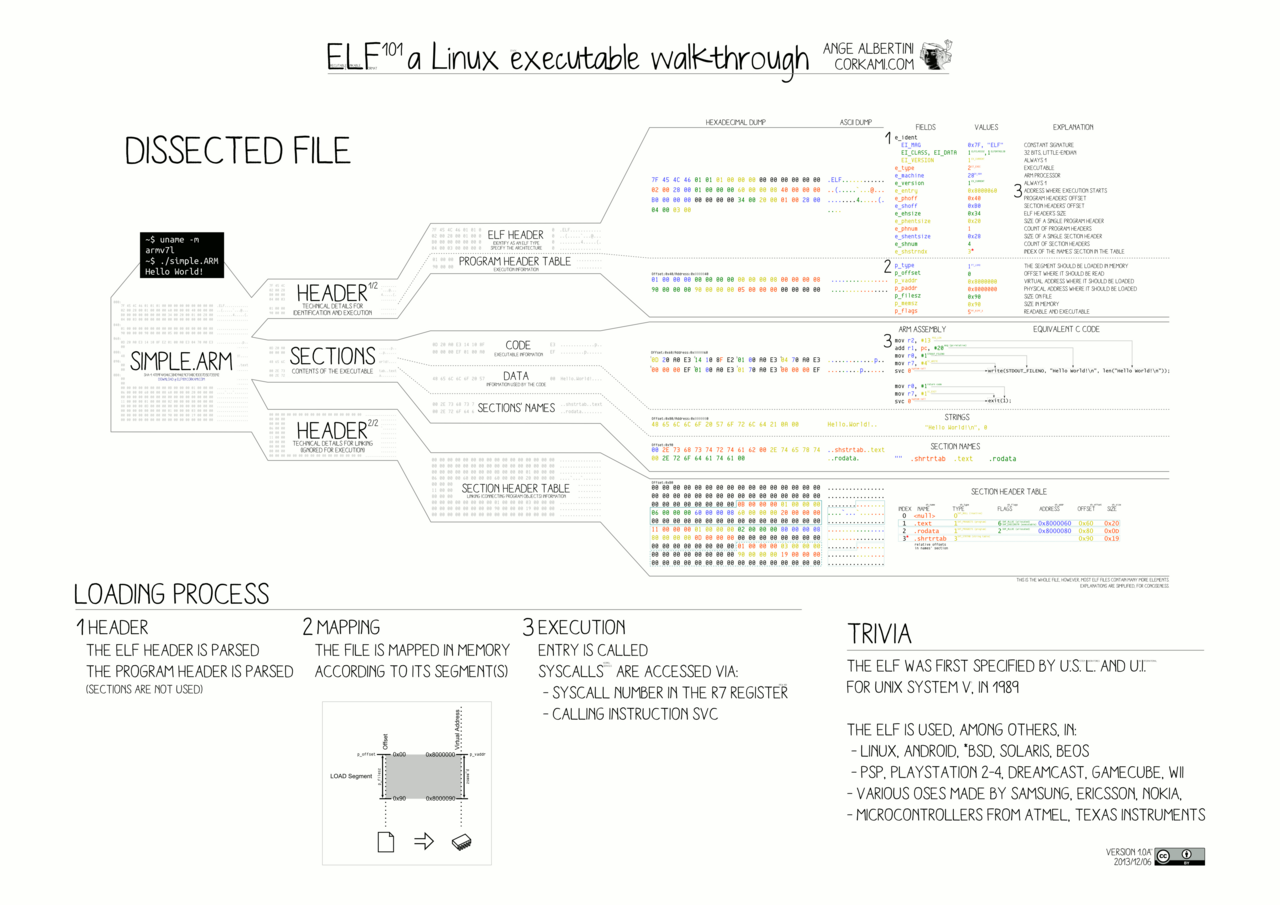
{kind=link}
When we compile our program, we may have multiple object (.o) files, that we must combine together to get our final executable.
It is the linker’s responsibility to combine them together in a coherent way to form an ELF file.
Let’s poke around our linker configuration file for the N64 to understand what is happening.
We’ll explore the default linker script of Libdragon, originally n64ld.x, developed by Frank Somers, with modifications by hcs.
/* Start address of code is 1K up in cached, unmapped RAM (KSEG0). We have
* to be at least this far up in order to not interfere with the cart
* boot code which is copying it down from the cart
*/
__libdragon_text_start = __kseg0_start + 0x400;
MEMORY
{
mem : ORIGIN = __kseg0_start, LENGTH = 4M
}
SECTIONS {
// Our sections, which we'll get to in a moment
You’ll notice the MEMORY definition, where we define one region of memory, which is 4MB, corresponding to the N64’s memory.
If our linker finds that it requires more than this for our program, then it will crash with an error.
Let’s look at the SECTIONS definition too:
SECTIONS {
/* The text section carries the app code and its relocation addr is
* the first byte of the cart domain in cached, unmapped memory
*/
.text __libdragon_text_start : {
*(.boot)
. = ALIGN(16);
__text_start = .;
*(.text)
*(.text.*)
*(.init)
*(.fini)
*(.gnu.linkonce.t.*)
. = ALIGN(16);
__text_end = .;
} > mem
.eh_frame_hdr : { *(.eh_frame_hdr) } > mem
.eh_frame : {
__EH_FRAME_BEGIN__ = .; /* Define symbol for accessing eh_frame section */
KEEP (*(.eh_frame))
} > mem
.gcc_except_table : { *(.gcc_except_table*) } > mem
.jcr : { KEEP (*(.jcr)) } > mem
.rodata : {
*(.rdata)
*(.rodata)
*(.rodata.*)
*(.gnu.linkonce.r.*)
. = ALIGN(8);
} > mem
/* This is important to keep __CTOR_END__ consistent */
. = ALIGN(4);
// other sections
You’ll note that our .rodata (read-only data, including our DNN weights) is being stored in mem, so if they exceed 4MB then our linker will crash.
It’s difficult to find a DNN with less than 4MB of weights, so this is going to be a problem.
Why does MicroTVM store the weights in the ELF file like this, when it’s targeting memory constrained microcontrollers? The reason for this is demand paging.
In newer systems, especially in memory constrained environments, the OS is often configured to only load data as it is required (pages at a time). This means that for most of the microcontrollers that MicroTVM targets, it doesn’t load all of the weights at once. Instead, they will be kept in the storage medium, and when a piece of code access that range of the weight array, the OS will load that page of data, and free it when it is not needed.
Unfortunately, the N64 does not really have a concept of demand paging like this.
We’re actually programming on bare metal, and we need to embed a small OS into our .z64 file.
Therefore, in the case of the N64, we load the entire ELF file into memory at once, and if it that’s more than 4MB, our linker file won’t generate it.
But hold on a second! You’ll recall in the first post that the N64 has unified memory. One thing that means is that our cartridge (our storage medium for our game) is memory mapped, and thus addressable. The cartridge can hold much more than our memory, potentially hundreds of MBs.
Could we edit our linker script so that we store our .rodata on the cartridge region of memory, rather than the main memory region?
Yes!
Let’s just add a new section to MEMORY called cartridge, and store our .rodata on it.
As you can see on this page of the N64brew wiki, the cartridge region of memory starts at 0x10000000.
But because of the way addressing works on the N64 (even though we have a 64-bit addressing mode, most programs address in 32-bit), we need to use a translation.
MEMORY
{
mem : ORIGIN = __kseg0_start, LENGTH = 4M
cartridge : ORIGIN = 0x00000000, LENGTH = 32M /* Adjust to actual cart size */
/* cartridge : ORIGIN = 0x10000000, LENGTH = 32M */
}
SECTIONS {
// rest as previous
.rodata : {
*(.rdata)
*(.rodata)
*(.rodata.*)
*(.gnu.linkonce.r.*)
. = ALIGN(8);
} > cartridge AT> mem /* note we are storing in a new place now */
Great, this looks like it could work, meaning we can now fit an (almost) arbitrary number of weights in our program, since they are stored in the cartridge. However, let’s take a step back and think about what would be happening here…
Our weights are now stored in the cartridge region.
So if we access constant_0_let[0], instead of loading it from main memory we fetch it from cartridge.
And this is super slow, and will thus be unacceptable for our DNN inference application.
Repeated accesses may also be slow, since there’s no guarantee that our arrays will be cached.
Do you remember loading screens in video games?
This is what they were for, and oh boy do we not want to have one for every parameter we load.
Accessing data from the cartridge on-demand is not workable — the latencies are too high.
Instead we should copy the data to main memory when it is needed, and free it when we are done with it. If we had some sort of demand pager that copied the arrays over to main memory when required, then we could fix the performance issue we have introduced. However, 1. this would be a relatively complex system to implement, 2. I’m lazy (in the pragmatic way!), and 3. we know the access patterns to our weights ahead-of-time. Perhaps there’s a simpler solution?
The answer is yes: weight serialisation. By saving our weights as files, we can store them on our cartridge, and load them into memory when required. Libdragon has a great little filesystem implementation for just this purpose. A simple loading schedule would be to load them just before we execute the layer that requires them, and free them when the layer has been executed. But a more advanced schedule would load the maximum amount of weights we can fit in 4MB, and hide the loading latency by loading new weights asynchronously. Let’s look at how we would implement this.
Implementing just-in-time weight loading
Code generation
Our end state should be an extension to our code generator, such that it produces something like the below function, where we load and freeing the weights from file before they are required in a given layer.
TVM_DLL int32_t tvmgen_default___tvm_main__(
float *dense_4_input_buffer_var, float *Identity_buffer_var,
uint8_t *global_const_workspace_0_var, uint8_t *global_workspace_1_var) {
// constant_X_let are our weight matrices, which we access load from
// the cartridge, a contiguous memory region with all our weights
// in it
void *constant_0_let; // forward declaration of weights
void *constant_1_let;
void *constant_5_let;
void *constant_2_let;
void *constant_3_let;
void *constant_4_let;
// sid_X_let are our intermediate results, which we store in a workspace
// buffer
void *sid_1_let = (&(global_workspace_1_var[96]));
void *sid_4_let = (&(global_workspace_1_var[0]));
void *sid_7_let = (&(global_workspace_1_var[64]));
// We then execute every layer of our model one after another, returning 0 if
// the execution was successful. Our output should be stored in
// Identity_buffer_var
if (tvmgen_default_fused_reshape(dense_4_input_buffer_var, sid_1_let,
global_const_workspace_0_var,
global_workspace_1_var) != 0)
return -1;
if (read_file_into_memory("rom:/constant_0_let.dat", &constant_0_let) != 0) return -1;
if (read_file_into_memory("rom:/constant_1_let.dat", &constant_1_let) != 0) return -1;
if (tvmgen_default_fused_nn_contrib_dense_pack_add_nn_relu(
sid_1_let, constant_0_let, constant_1_let, sid_4_let,
global_const_workspace_0_var, global_workspace_1_var) != 0)
return -1;
free constant_0_let;
free constant_1_let;
if (read_file_into_memory("rom:/constant_2_let.dat", &constant_2_let) != 0) return -1;
if (read_file_into_memory("rom:/constant_3_let.dat", &constant_3_let) != 0) return -1;
if (tvmgen_default_fused_nn_contrib_dense_pack_add_nn_relu_1(
sid_4_let, constant_2_let, constant_3_let, sid_7_let,
global_const_workspace_0_var, global_workspace_1_var) != 0)
return -1;
free constant_2_let;
free constant_3_let;
if (read_file_into_memory("rom:/constant_4_let.dat", &constant_4_let) != 0) return -1;
if (read_file_into_memory("rom:/constant_5_let.dat", &constant_5_let) != 0) return -1;
if (tvmgen_default_fused_nn_contrib_dense_pack_add(
sid_7_let, constant_4_let, constant_5_let, Identity_buffer_var,
global_const_workspace_0_var, global_workspace_1_var) != 0)
return -1;
free constant_4_let;
free constant_5_let;
return 0;
}
How can we achieve that?
First, let’s dump the weights of our DNN to file.
Before we automate this in our codegen stage, I wrote a wee Python script to parse our generated .c file.
You can see it on this gist, but it isn’t necessary to read it.
All it does is convert our weight arrays to binarised .dat files, which can be loaded by our C program.
We also generate a .csv file for manual visual inspection.
But we don’t use this in our program, since parsing the raw text of a CSV would be more expensive than loading binary data.
Next, we must figure out where in our code generation pipeline to insert our loading and freeing code.
Like most compilers, TVM represents its computation as an AST (abstract syntax tree), and then translates that to the appropriate format for the chosen backend.
For our C backend, this it the CodeGenC class, in target/source/codegen_c.[cc/h].
This subclasses CodeGenSourceBase, and inserts the appropriate C code given its walk of the AST.
For example, here’s how it handles generating the code for a while loop.
void CodeGenC::VisitStmt_(const WhileNode* op) {
PrintIndent(); // Adds indentations to our source file
stream << "while (1) {\n"; // We are just printing our C to an output stream
int while_scope = BeginScope();
std::string cond = PrintExpr(op->condition);
PrintIndent();
stream << "if (!(" << cond << ")) { break; }\n";
PrintStmt(op->body); // Our body can be arbitrary, so other VisitStmt_ may
// be called before we return from here
this->EndScope(while_scope);
PrintIndent();
stream << "}\n";
}
We want to preserve all of this functionality, but have a special case for loading our weights when we are in the main function. We can check if we are in the main function by editing the AddFunction method.
Our assignments (e.g., void *constant_0_let = (&(global_const_workspace_0_var[1216]));) are generated when handling LetStmtNodes.
But we don’t want to completely replace it, since we only want this behaviour in our main function for our weights, and leave the default behaviour otherwise.
We could subclass CodeGenC, but instead I’m going to use a “State” design pattern (discussed here).
This is where we switch out the implementation for a given subset of our class’s functions with a state change.
Most of the time we will use the original implementation, but if we are generating the main function we use a different one.
Crucially, any visits we do to subsequent nodes of types other than LetStmtNode will still use the original version (unless we also override them).
I’ll discuss the tradeoffs of using this pattern versus just subclassing when I try and upstream this feature into TVM.
I chose it here because it was easier to implement.
We could have some code generation look something like:
void DefaultVisitorState::VisitStmt_(const LetStmtNode* op, CodeGenC* codegen) {
// Original code
}
void MainFuncVisitorState::VisitStmt_(const LetStmtNode* op, CodeGenC* codegen) {
// For our weight arrays, instead of printing to a stream,
// store in std::unordered_map<std::string, std::string> load_var_code_
// where the key is the var_name. We will print later
// we will store our code for later use
// Workspace accesses are printed as normal
auto& var_idmap_ = codegen->var_idmap_;
auto& handle_data_type_ = codegen->handle_data_type_;
std::string value = codegen->PrintExpr(op->value);
std::string var_name = codegen->AllocVarID(op->var.get());
std::string dtype = "void";
std::ostringstream stream;
// misc code
stream << " static " << dtype;
stream << "* " << var_name << "; // Declare without immediate initialization \n";
// Open file to read binary data
stream << " if (read_file_into_memory(\"rom:/" << var_name << ".dat\", &" << var_name
<< ") != 0) return 0;\n\n";
load_var_code_[var_name] += stream.str();
}
If we were to just print to our regular output stream, we would have a problem, namely because of the structure of the AST, all of the loads are generated when the variables are defined — before any of our computation occurs. This defeats the purpose of our lazy-loading structure, and we wouldn’t save any memory.
Instead, we should generate code for our variable declarations, and generate our loading code later (saved in a map/dictionary load_var_code_).
Using our simple scheduling, we will generate that code right before we require the given weight array for a layer invocation.
Our layer invocation code is generated in VisitStmt_ for CallNodes.
Let’s inject our array loading code before the invocation, and our free statements afterwards.
Note that we need to inspect the variables used by the layer invocation to identify what load and free code we should generate.
So something like:
// Target example
// if (read_file_into_memory("rom:/constant_0_let.dat", &constant_0_let) != 0) return -1;
// if (tvmgen_layer(
// sid_1_let, constant_0_let global_const_workspace_0_var,
// global_workspace_1_var) != 0)
// return -1;
// free constant_0_let;
const CallNode* call = op->args[2].as<CallNode>();
if (main_state) main_state_->LoadArrays(call, this); // load any arrays that might be needed
os << "if (";
VisitExpr_(call, os);
os << " != ";
PrintExpr(op->args[0], os);
os << " ) return ";
PrintExpr(op->args[1], os);
if (main_state) {
// free any arrays that we don't need
os << ";\n";
main_state_->FreeArrays(call, this, os);
};
And with that, our code is being generated correctly, matching our target at the top of this section.
Weight serialisation
Now that we are generating our code correctly, we should add a step to automatically serialise our weight arrays to file in our compiler, rather than having to do it manually.
The part of TVM responsible for exporting our weights is target/source/source_module.cc.
To extend this with dump-to-file capabilities, we should really add a compilation flag (e.g., serialize_weights), but I’m just going to comment out the original functionality.
TVM represents the weights as an NDarray object, which stores information on the number of elements, the shape, and the data type. The code for this could be something like:
void GenerateBinarisedArray(const std::string& name, const runtime::NDArray& array,
int64_t nelems) {
std::vector<float> out_data(nelems);
array.CopyToBytes(out_data.data(), nelems * sizeof(float));
// Save the data to a file
std::string filePath = "./filesystem/" + name + ".dat";
std::ofstream outFile(filePath, std::ios::binary);
if (!outFile) {
std::cerr << "Cannot open file for writing: " << filePath << std::endl;
return;
}
// Write to file
for (float value : out_data) {
char* floatToConvert = reinterpret_cast<char*>(&value);
outFile.write(reinterpret_cast<const char*>(&value), sizeof(float));
}
outFile.close();
}
Remember, we also need to remove the code generation for the .rodata allocations of the weight arrays, otherwise we won’t save any memory.
Now, our compiler should now do everything we need to implement the lazy weight-loading system!
A fun bug
But there’s just one issue. Our weights should look like this:
-0.322642, -0.193584, -0.039593, 0.241229, -0.208302, 0.326660, 0.284028, -0.062102, -0.288896, -0.225929
But when we load and print them on the N64 we get this:
3125206646259712.000000, -12500793344.000000, -13884177169667107456764597791358976.000000, -0.000000, 0.000000, -57923652611791493277941760.000000, 0.000000, 275435557443501243583439044608.000000, 0.114540, 0.000000
What could be happening, why are they different? Is there a bug in our weight file loading code, or our serialisation?
It doesn’t seem like it — if we run the loading code as a standalone C program on my laptop, using the exact .dat files, then we get the correct output.
So what’s happening? Why is the N64 interpreting this data differently? I’ve spoiler tagged the answer, because I think it’s mildly interesting, and can be worked out from the information I’ve given you already.
Click to reveal the answer
The answer is endianness!
Most modern machines (including x86 and ARM) default to a little-endian representation of data.
However, the N64 with its MIPS CPU uses a big-endian format.
That means that it is reading our bytes for a given element in reverse order.
So it would read the little-endian number 0000 0011 0111 1111 as 0111 1111 0000 0011.
This explains why our small numbers on the laptop are large when loaded on the N64.
By reversing the order of the bytes on our export we now get the correct outputs!
Conclusions
This post outlines how we can overcome the 4MB limit of the N64 when running large DNNs by storing the weights as binarised files on our cartridge, and only loading them when needed. The original design of our compiler assumed that we had access to some sort of OS level demand paging for ELF files, but to date no such functionality exists for the N64. Therefore we generate the code to do this ourselves.
Note that we rely on the filesystem utilities available in Libdragon, which is why we prepend our paths with rom:/.
We need to enable this feature in our Makefile, so it knows to copy over any of our .dat files into the .z64 cartridge files we generate.
You can see an example of working with the Libdragon filesystem here.
As discussed above, we could further optimise this feature by being more intelligent with our weight loading schedule, and doing so asynchronously. This solution is almost space optimal — we only load weights when they are required, but it isn’t time optimal. But for now, it’s good enough that we can now generate working code for larger models on the N64. The only way we could get more space optimal would be to load partial weight arrays, but that would be a more complex scheduling problem.
In the next post, we’ll discuss the issue of the memory requirements of the intermediate activations. For now, catch ye.